
Introduction
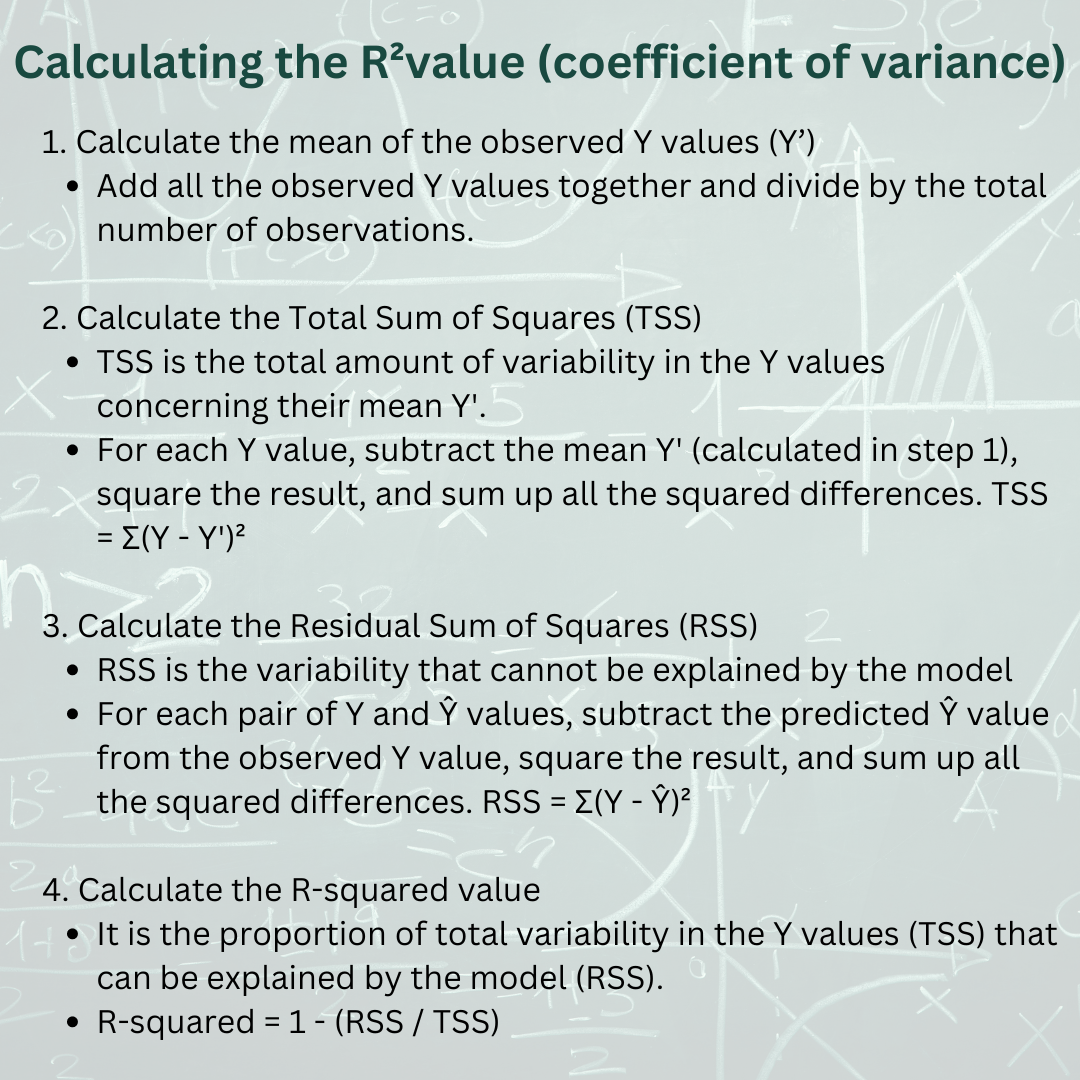
The coefficient of variance (R2 value) is a measure used in statistics that represents the amount of variance in the outcome which can be explained by the independent variable(s). It is commonly used in regression models.1 It is a value ranging from 0.00 (0%) to 1.00 (100%), with 0.00 meaning that the model explains none of the outcome, and 1.00 indicating a perfect fit.2 It can be calculated using the variables mean of the observed Y values (Y’), Total Sum of Squares (TSS), and Residual Sum of Squares (RSS) [Figure 1].

If the R2 value is closer to 1.0, then more of the fluctuation in the response (dependent) variable is strictly due to change in the predictor (independent) variable(s). Thus, the independent variable(s) in the model explain more of the variation of the dependent variable. Alternatively, as the R2 value nears 0.0, it implies a weaker relationship between the independent variable(s) and the outcome.3 This suggests that the model’s predictions are not well-aligned with the actual data points. Thus, the independent variable(s) may not have much explanatory power concerning the variation observed in the dependent variable.2 When the R2 value is exactly 1.0, a perfect linear relationship exists between the independent variable(s) and the outcome. In this case, all data points fall exactly on a straight line, and the model provides a perfect prediction.4 While this may seem ideal, it can also mean the model is “overfitting”, which is a potential pitfall especially in the case of multivariate linear regression.5 Put simply, overfitting can occur in two major ways. Firstly, the model is trained on a dataset that does not resemble the general population, and thus the model does not fit well when applied to new data. Second, if the model has more independent variables than data points, the model will necessarily always have a perfect fit, though this is unrealistic.5 The latter point occurs because each variable can, in essence, be ‘assigned’ to a data point, such that the model will be able to perfectly “memorize” the dataset, resulting in a perfect fit for the training data.6 However, this memorization does not generalize to new or unseen data. This is because the model essentially captures noise or random fluctuations in the training data, rather than underlying patterns or relationships. When tested on a new dataset, the model fails to accurately predict outcomes because the noise it captured is not present in the new data.7 To avoid overfitting, techniques such as cross-validation, regularization, and reducing the number of variables can be employed. These approaches help ensure that the model captures general trends rather than specific quirks of the training data, improving its generalizability to unseen data.
In various fields, “good” R2 values have different meanings. In the social sciences and psychology fields, where the behaviors of human subjects pose challenges, values as low as 0.10 to 0.30 are often considered acceptable.8 The field of finance has a much larger range with “good” R2 values ranging from 0.40 to 0.70,9 depending on the nature of the analysis and data availability. Physical sciences and engineering generally expect higher R-squared values, above 0.70 to be considered good. Scientists in physics and chemistry generally consider 0.70–0.99 a “good” R2 value.10 Pure mathematics doesn’t directly apply R2 values, but when relevant, values should be close to a perfect 1.00 to indicate a data-model fit. In ecology, R2 values can vary; values from 0.20 to 0.50 are considered acceptable or good, tailored to the specific research question and ecological context.11 The field of medicine, however, does not have much conclusive data on this topic and researchers often use arbitrary bounds.12
Review
Interpreting R2 in the context of clinical medicine
To establish a benchmark for a ‘good’ R-squared value, a comprehensive review of the medical literature was conducted. In “Quantifying health”, Dr. Chouiry examined over 43,000 papers in PubMed and noted that only a third of the papers that used linear regression even reported the R2 value.13 Therefore over 66% of published studies that utilize linear regression do not report this key statistic. The distribution of the R2 values in the papers reviewed had a bimodal distribution, with 10% of papers having an R2 < 0.035. One of the most significant findings was that the value of the R2 (including high and low outliers) had no correlation to the impact factor of the journal. To place this information in the context of medicine, we looked at studies that informed a few of the bread-and-butter acute diagnoses seen in the emergency department: cardiac arrest, stroke, sepsis and head injury, with the idea that a narrower range of typical R2 values may emerge.
Cardiac arrest
Out-of-hospital cardiac arrest is a condition with high mortality and poor outcomes even in settings where extensive emergency care resources are available.14 A 2020 study of pediatric cardiac arrest in the United States found that predictors of survival to hospital discharge included female sex, number of minutes from collapse to the arrival of EMS, age (in months), and use of an advanced airway to be predictors in a regression model with an R2 of 0.245.15 Similarly, an adult cardiac arrest study from Croatia reported a logistic regression analysis for the return of spontaneous circulation (ROSC) to hospital admission, which included the following 5 factors: age, sex, adrenaline use, rhythm conversion and bystander CPR. This model had an R2 of 0.217.16
Intracerebral hemorrhage
Intracerebral hemorrhage (ICH) is the most devastating form of stroke. According to the World Stroke Organization, There are over 3.4 million new ICH cases each year. Globally, over 28% of all incidental strokes are intracerebral hemorrhages.17,18 In a study comparing the ICH scores between men and women at ED arrival, the regression model comprised 16 factors including age, race sex, atrial fibrillation, hypertension, dyslipidemia, diabetes, smoking, independence in activities of daily living (ADLs), median BMI, median systolic and diastolic blood pressures, median hemoglobin A1C (HbA1C), median Glasgow Coma Score (GCS), median NIHSS, and arrival method. Each individual factor was not necessarily significant in univariate analysis. The overall multivariate model had a R2 of 17%.19
A study of patients undergoing cranioplasty (CP) after decompressive craniectomy following ICH examined the predictive factors for procedural complications and found that a history of primary coagulopathy, intraoperative ventricular puncture, and intraoperative dural limit violation were associated with increased surgical complications. It additionally found that patients who lived at home at the time of CP had a reduced likelihood of post-CP surgical complications. This model explained 20% of the variance in post-CP complications (R2=0.20).20
Sepsis
Sepsis is the primary cause of death due to infection.21 It is one of the most frequent causes of death worldwide, with 48.9 million cases and 11 million sepsis-related deaths worldwide, representing 20% of all global deaths.22 A prospective study of heart rate variability as a predictor of mortality in sepsis reports on a model with an R2 of 0.167. The Sequential Organ Failure Assessment (SOFA) Score were the elements in the model and included: FiO₂ level, mechanical ventilation, and platelet count.23
A 2020 study examined the appropriateness of empirical antibiotics in patients with sepsis in the ICU. The simple linear regression indicated that appropriate empirical antibiotics were associated with decreasing ICU length of stay, with a model R2 of 0.055. By contrast, the use of inappropriate antibiotics was associated with a worse APACHE-II score, with an R2 of 0.079.24
Head injury
Traumatic brain injury (TBI) is a prevalent condition with over 214,110 TBI-related hospitalizations in 2020 and 69,473 TBI-related deaths in 2021 in the United States alone.25 The most common etiologies are falls and road traffic accidents.26
A retrospective observational study of over 800 patents examined the impact of seatbelt in motor vehicle associated head injury. Model variables included sex, alteration or loss of consciousness, vomiting, consumption of alcohol before the accident, and arrival via EMS. Three separate models with the outcomes of TBI severity, abnormal brain CT and ICU admission were built, with R2 values of 0.261, 0.228, and 0.208 respectively.27
The prospective longitudinal observational Collaborative European NeuroTrauma Effectiveness Research in Traumatic Brain Injury (CENTER-TBI) study examined factors associated with good Glasgow Outcome Score 6 months post injury. The model included age, Glasgow Coma Score, and injury severity score (ISS), resulting in a model with an R2 of 0.18. Adding sex, American Society of Anesthesiologists Physical Status (ASA Class), psychiatric history, cause of injury, and pupillary reactivity, to the model resulted in an R2 of 0.21.28

Summary of Findings
The above studies cover various pathologies, across various journals and disciplines, and converge around an R2 of ~20%. Given that much of clinical medicine is impacted by humans’ psychosocial underpinnings, a value of >15% is likely to be a reasonable threshold, providing that each of the individual variables in the model are significant4 [Figure 2].
Understanding the limitations of the R2 value in clinical medicine is critical. Medical outcomes are most often formed as a culmination of numerous complex factors, and relying solely on an R2 value could oversimplify these non-linear relationships. When dealing with limited sample sizes and large numbers of predictors, a risk of overfitting exists, which inflates R-squared values and compromises the model’s generalizability to new data.6 Researchers should utilize R-squared alongside other statistical tests to avoid biases and inaccuracies.
“What is a good R-squared value in clinical medicine” is the classic question that begets the answer “it depends.” Occasionally there is value in explaining only a very small fraction of the variance, particularly when outcomes are multifactorial such as the natural history of a disease.29 The interpretation of R-squared values should be carefully considered within the specific context of the study design and the characteristics of the investigated population. While higher R-squared values may suggest a better fit of the regression model to the data, the intricacies of clinical medicine warrant a cautious approach to interpreting such values. The establishment of a ‘good’ R-squared benchmark should be further refined through a meticulous review of additional literature to account for the diversity and complexity of clinical research studies. Perhaps the best guideline in interpreting the R2 for a particular research question is to base the target R2 value off of similar studies in the literature. As the benchmarks vary widely in clinical medicine, comparison with existing literature is paramount in understanding the significance of an R2 value that one may obtain in their own analysis.30
Conclusion
Through comparison of the data presented in the referenced articles, it is reasonable to consider an R-squared value of 0.15-0.20 (15-20%) as a suitable benchmark in clinical research, with many caveats. It is essential to acknowledge that the appropriateness of an R-squared benchmark can vary depending on the number and influence of factors contributing to the outcomes under investigation. Different studies may require specific R-squared thresholds to accurately gauge model performance and predictive capacity. Above all, R2 benchmarks vary widely by the particular research question being addressed, and the most accurate benchmark will always be achieved through comparison with existing literature on the specific research question being investigated. It is important to note that no R2 value tells you if a model is good or not; rather it tells you how well the model fits the data you have. To ensure robust and reliable results, researchers are encouraged to complement R-squared analysis with other relevant statistical tests and validation techniques. This comprehensive approach contributes to a more comprehensive evaluation of the regression model and enhances confidence in the study findings.